seven_tensors = [load(joinpath(data_path, "train", "7", seven)) for seven in sevens]three_tensors = [load(joinpath(data_path, "train", "3", three)) for three in threes]size(seven_tensors), size(three_tensors)
The rule of broadcasting in Julia is different from Python? In Python, first align all dimensions to the right, then broadcast. In Julia, first align all dimensions to the left, then broadcast. So in python [1000, 28, 28] - [28, 28] is allowed, but in Julia, we need [28, 28, 1000] - [28, 28]. Use permutedims to change the order of dimensions.
valid_threes =sort(readdir(joinpath(data_path, "test", "3")))valid_3_tens = MLUtils.stack([load(joinpath(data_path, "test", "3", img)) for img in valid_threes])valid_sevens =sort(readdir(joinpath(data_path, "test", "7")))valid_7_tens = MLUtils.stack([load(joinpath(data_path, "test", "7", img)) for img in valid_sevens])# valid_3_tens = permutedims(valid_3_tens, [3, 1, 2])size(valid_3_tens), size(valid_7_tens)
((28, 28, 1010), (28, 28, 1028))
functionmnist_distance(a, b) mm =mean(Float32.(abs.(a .- b)), dims=(1, 2))returndropdims(mm, dims=(1, 2))endmnist_distance(a_3, mean3)[1]
Taking gradients in Flux.jl is as simple as calling gradient on a function. For example, to take the gradient of f(x) = x^2 at x = 2, we can do the following:
f(x) = x^2df(x) =gradient(f, x)[1]df(2)
4.0
Below we implement and visualise gradient descent from scratch in Julia.
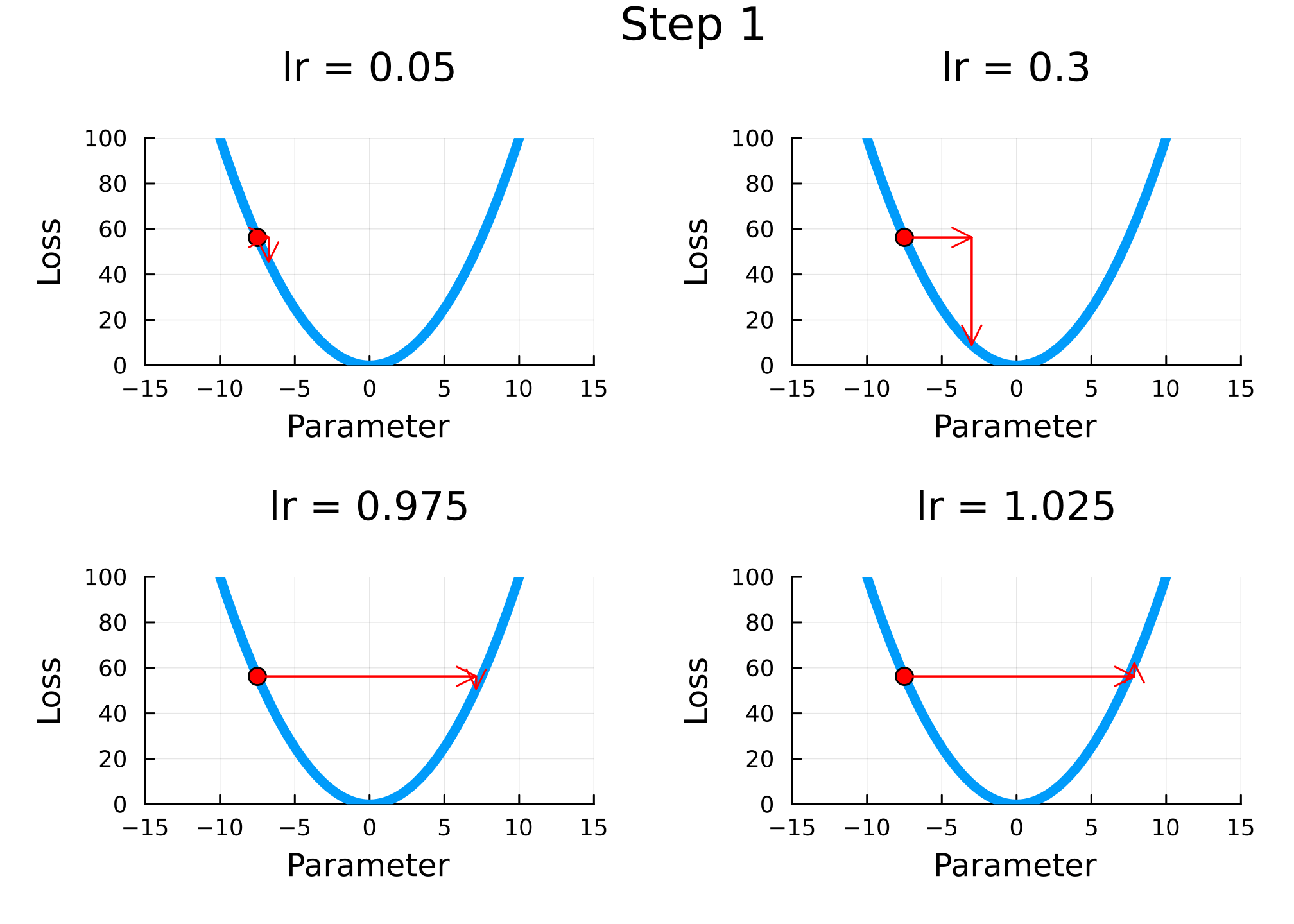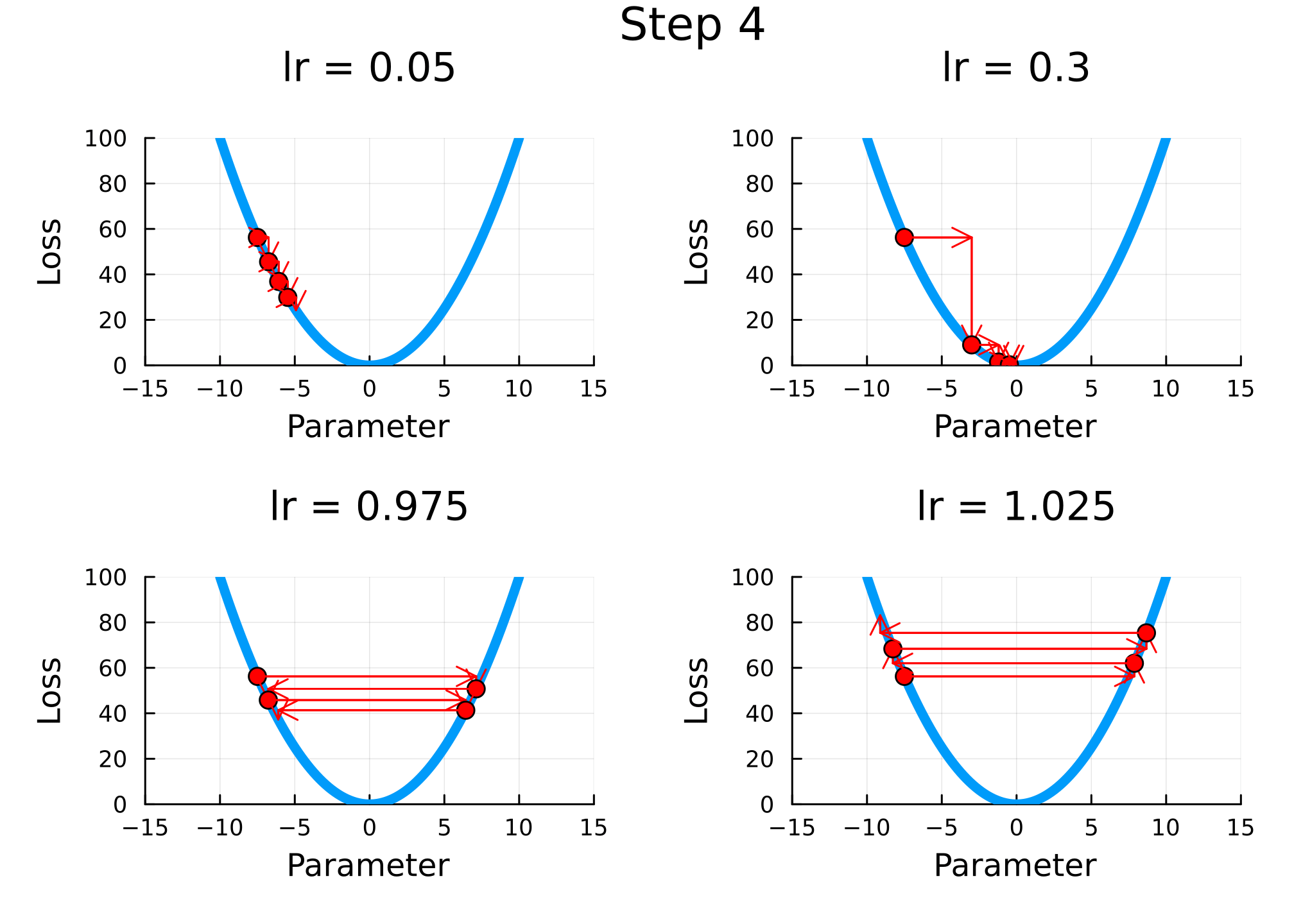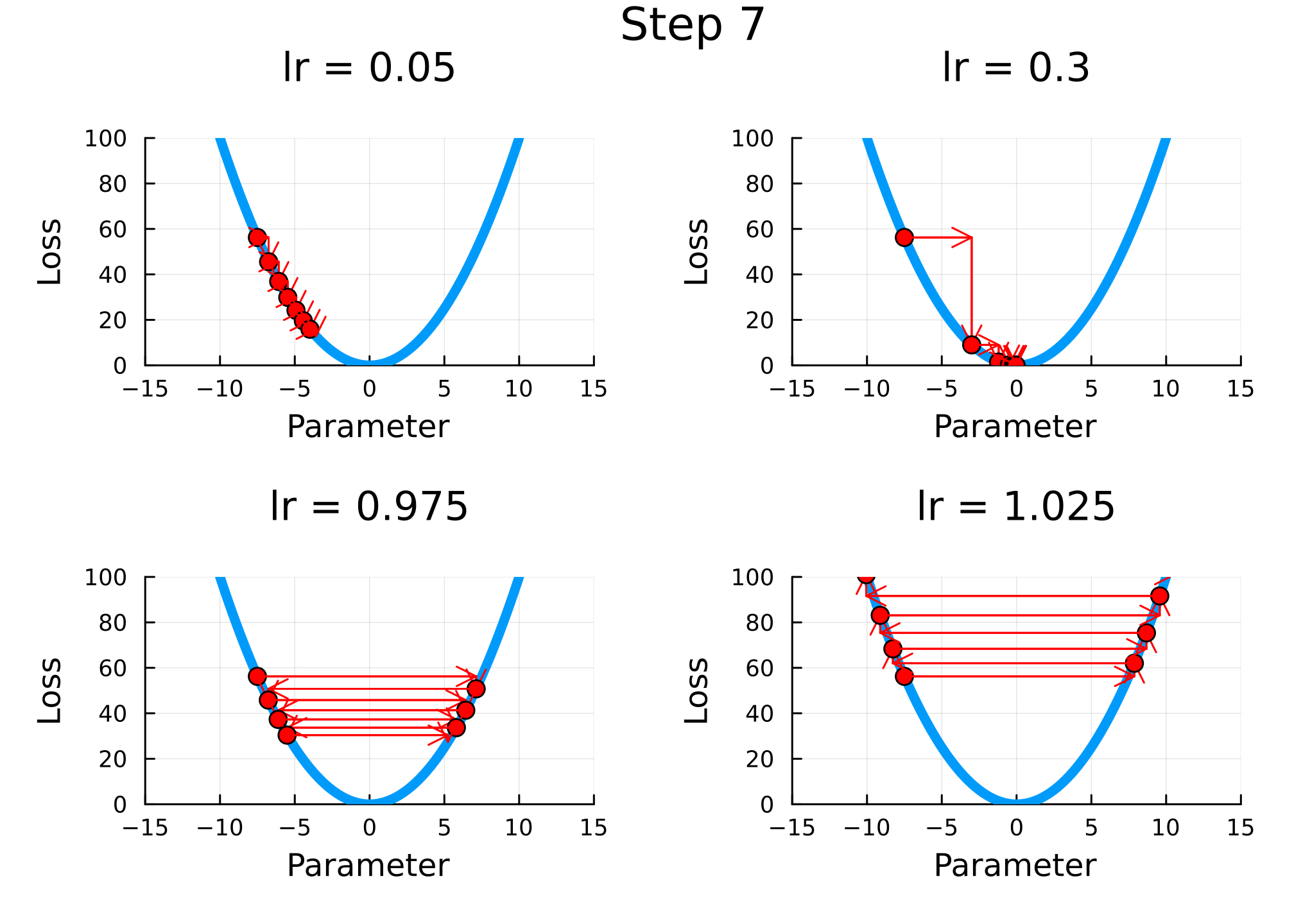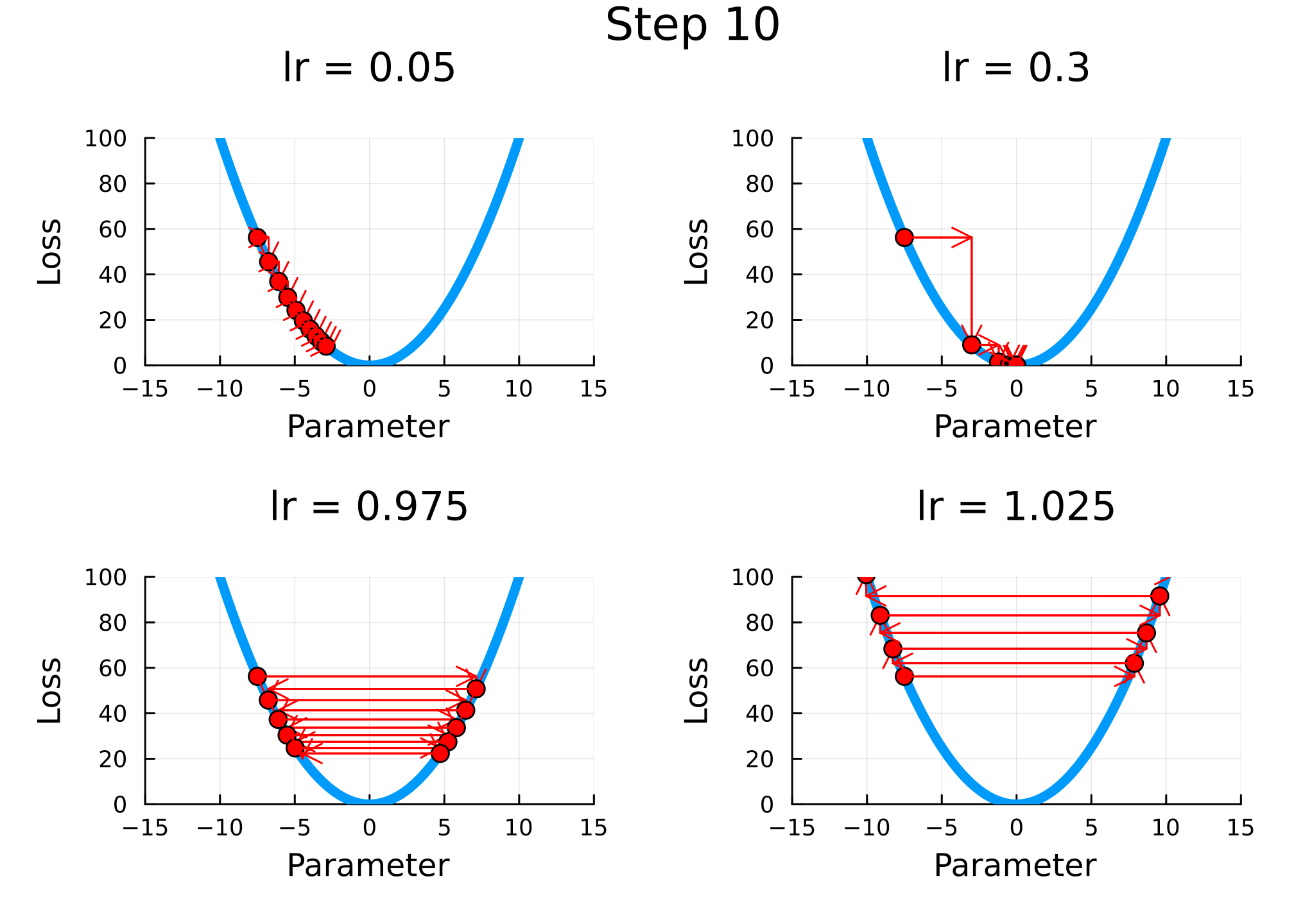
xmax =10n =100plt =plot(range(-xmax, xmax, length=n), f; label="f(x)", lw=5, xlim=1.5.* [-xmax, xmax], xlab="Parameter", ylab="Loss", legend=false)nsteps =10lrs = [0.05, 0.3, 0.975, 1.025]descend(x; lr=0.1) = x - lr *df(x)x = [-0.75xmax]x =repeat(x, length(lrs), 1) # repeat x for each learning rateplts = [deepcopy(plt) for i in1:length(lrs)] # repeat plt for each learning rateanim =@animatefor j in1:nstepsglobal x =hcat(x, zeros(size(x, 1))) # add column of zeros to xfor (i, lr) inenumerate(lrs) _plt =plot(plts[i], title="lr = $lr", ylims=(0, f(xmax)), legend=false)scatter!([x[i, j]], [f(x[i, j])]; label=nothing, ms=5, c=:red) # plot current point x[i, j+1] =descend(x[i, j]; lr=lr) # descend Δx = x[i, j+1] - x[i, j] Δy =f(x[i, j+1]) -f(x[i, j])quiver!([x[i, j]], [f(x[i, j])], quiver=([Δx], [0]), c=:red) # horizontal arrowquiver!([x[i, j+1]], [f(x[i, j])], quiver=([0], [Δy]), c=:red) # vertical arrow plts[i] = _pltendplot( plts..., legend=false, plot_title="Step $j", margin=5mm, dpi=300, )endgif(anim, joinpath(www_path, "c4_gd.gif"), fps=0.5)
Figure 2.1: Gradient descent for different learning rates
2.3 An End-to-End SGD Example
## is time a good variable name?time =collect(range(start=0, stop=19))speed = @. $rand(20) +0.75* (time -9.5)^2+1scatter(time, speed, legend=false, xlabel="time", ylabel="speed")
functionf(t, params) a, b, c = paramsreturn @. a * (t - b)^2+ cendfunctionmse(preds, targets)returnsum((preds .- targets) .^2) /length(preds)end
## params will be updated in placefunctionapply_step!(params; lr=1e-5, prn=true) grad =dloss(params)[1] params .-= lr * grad ## inplace update preds =f(time, params) loss =mse(preds, speed)if prnprintln(loss)println(grad)println(params)endreturn predsend
apply_step! (generic function with 1 method)
params =rand(3)plts = []for i inrange(1, 4)push!(plts, show_preds(apply_step!(params; lr=0.0001, prn=false)))endplot( plts..., legend=false, plot_title="First four steps", margin=5mm, dpi=300,)
params =rand(3)preds =f(time, params)plts = []push!(plts, show_preds(preds))lr =0.0001## how to adjust learning rate? takes a lot of time to learnfor i inrange(0, 60000)apply_step!(params, prn=false)endpreds =apply_step!(params, prn=true);push!(plts, show_preds(preds))plot( plts..., legend=false, plot_title="After 60000 steps", margin=5mm, dpi=300,)
Pytorch tensor provides a tag to indicate if gradient is to be computed. This is not needed in Flux? To get gradient, just use gradient function in Flux
lowercase_alphabets ='a':'z'## [Char(i) for i in 97:122]ds = [ (i, v) for (i, v) inenumerate(lowercase_alphabets)]dl =DataLoader(ds, batchsize=5, shuffle=true)collect(dl)
functiontrain_epoch(model, lr, params)for dd in dl xb, yb =reformat_dl(dd) grad =calc_grad(xb, yb, model, params)[1]for k inkeys(params) params[k] .-= grad[k] * lr## no need to zero_grad? in Pytorch, p.grad.zero_()endendendtrain_epoch(linear1, lr, params)
functionvalidate_epoch(model) accs =zeros(length(valid_dl)) i =1for dd in valid_dl xb, yb =reformat_dl(dd) accs[i] =batch_accuracy(model(xb, params), yb) i = i +1endreturnround(mean(accs), digits=4)endfunctiontrain_accuracy(model) accs =zeros(length(dl)) i =1for dd in dl xb, yb =reformat_dl(dd) accs[i] =batch_accuracy(model(xb, params), yb) i = i +1endreturnround(mean(accs), digits=4)end
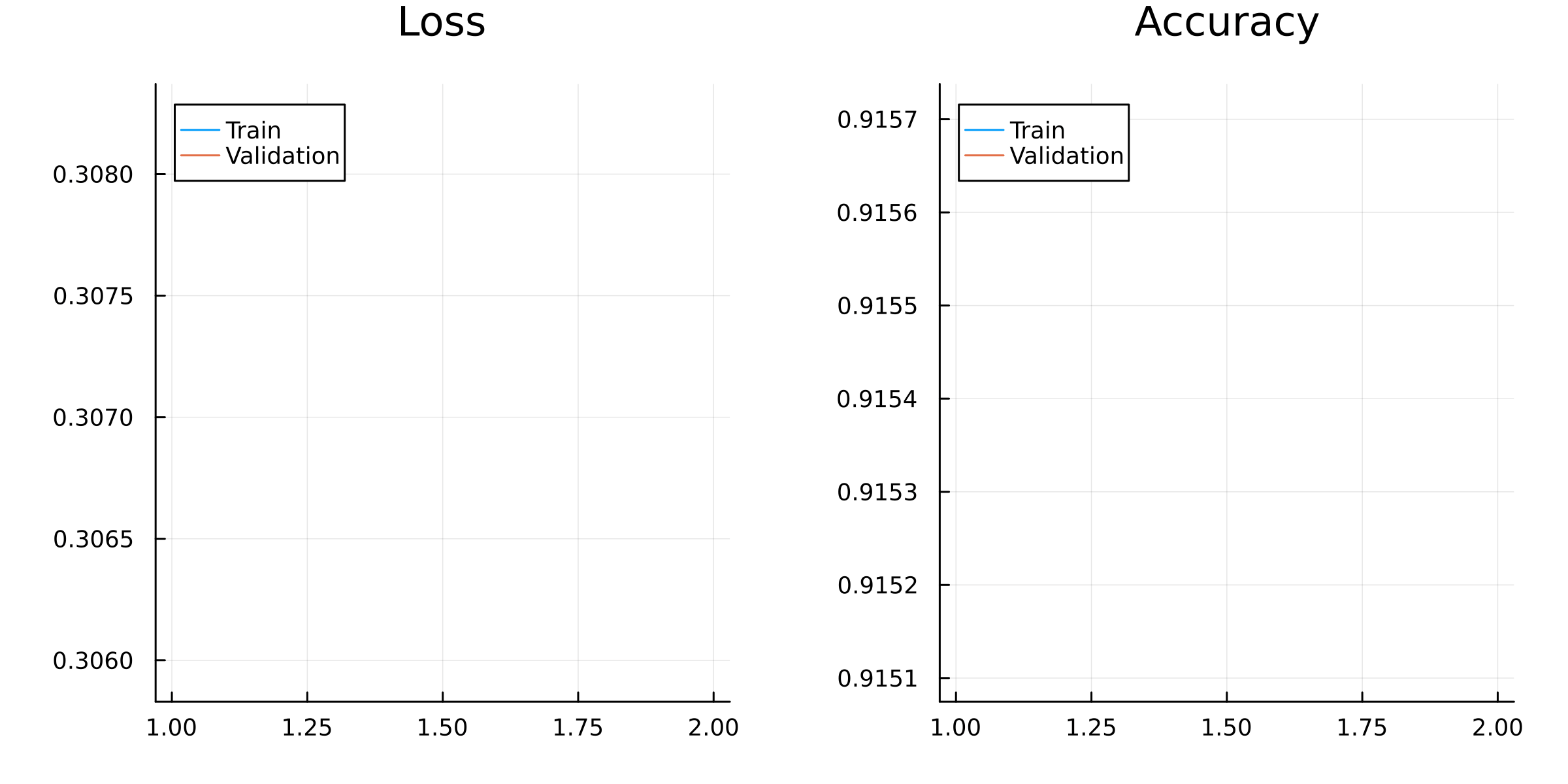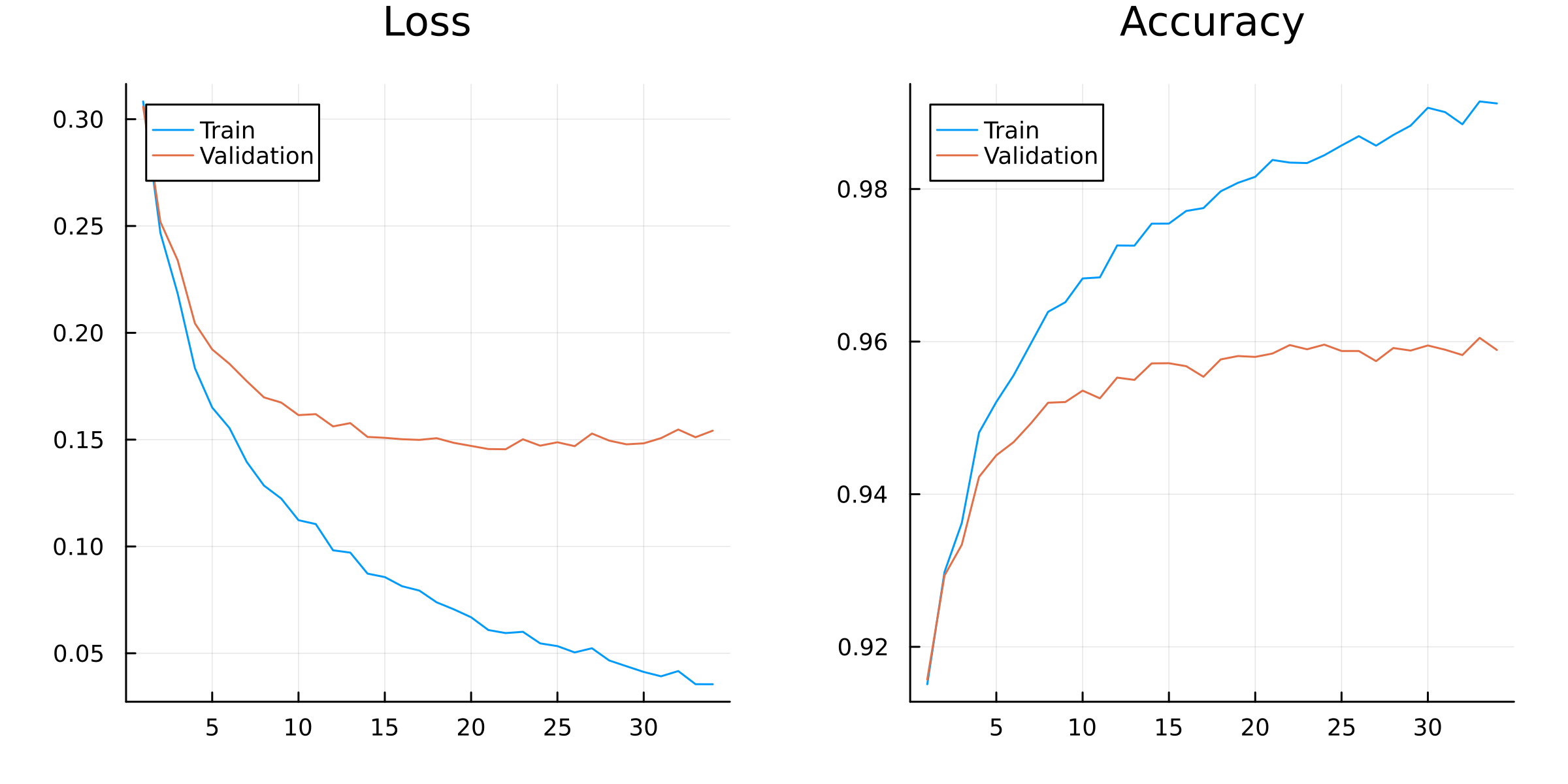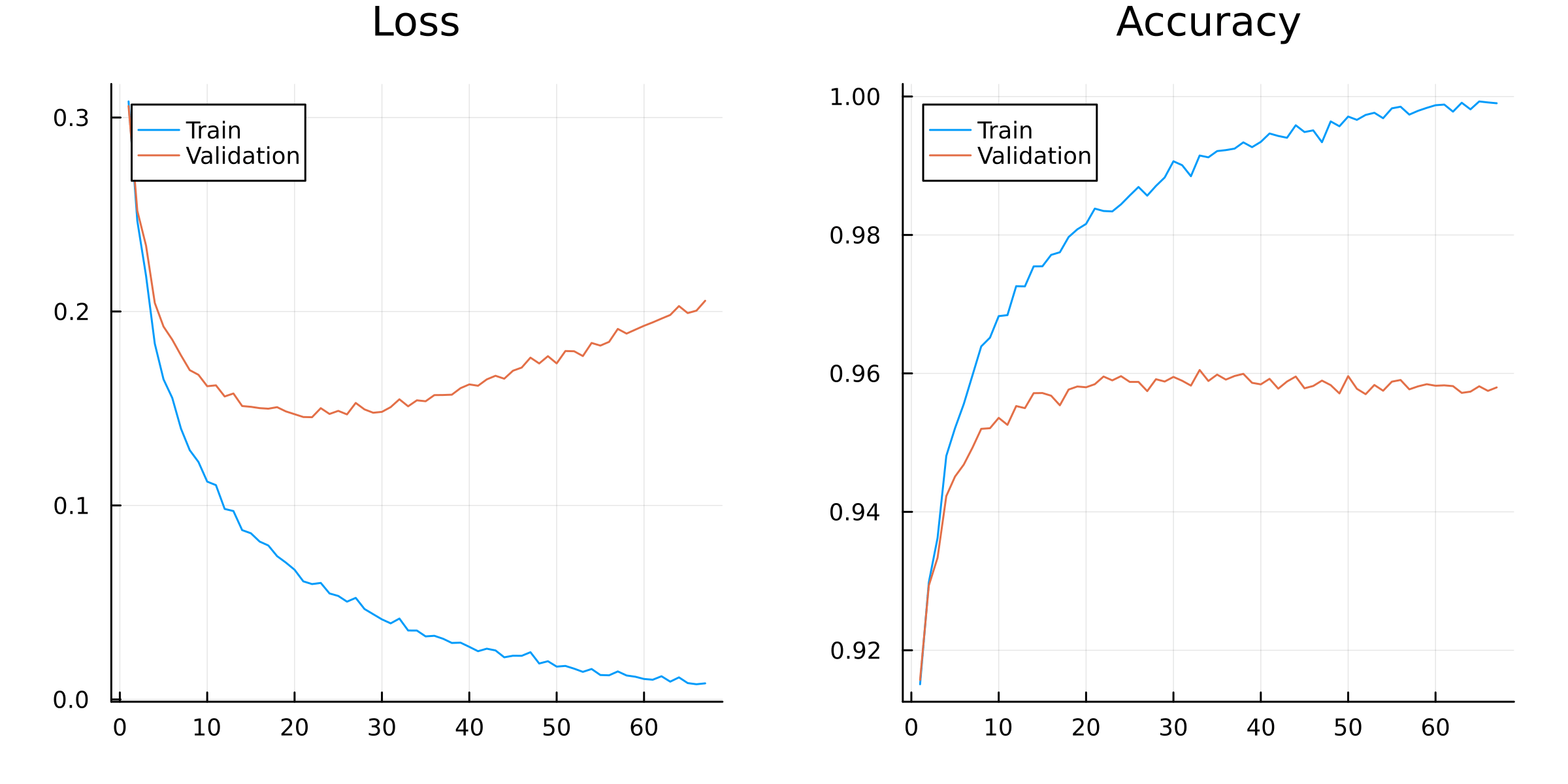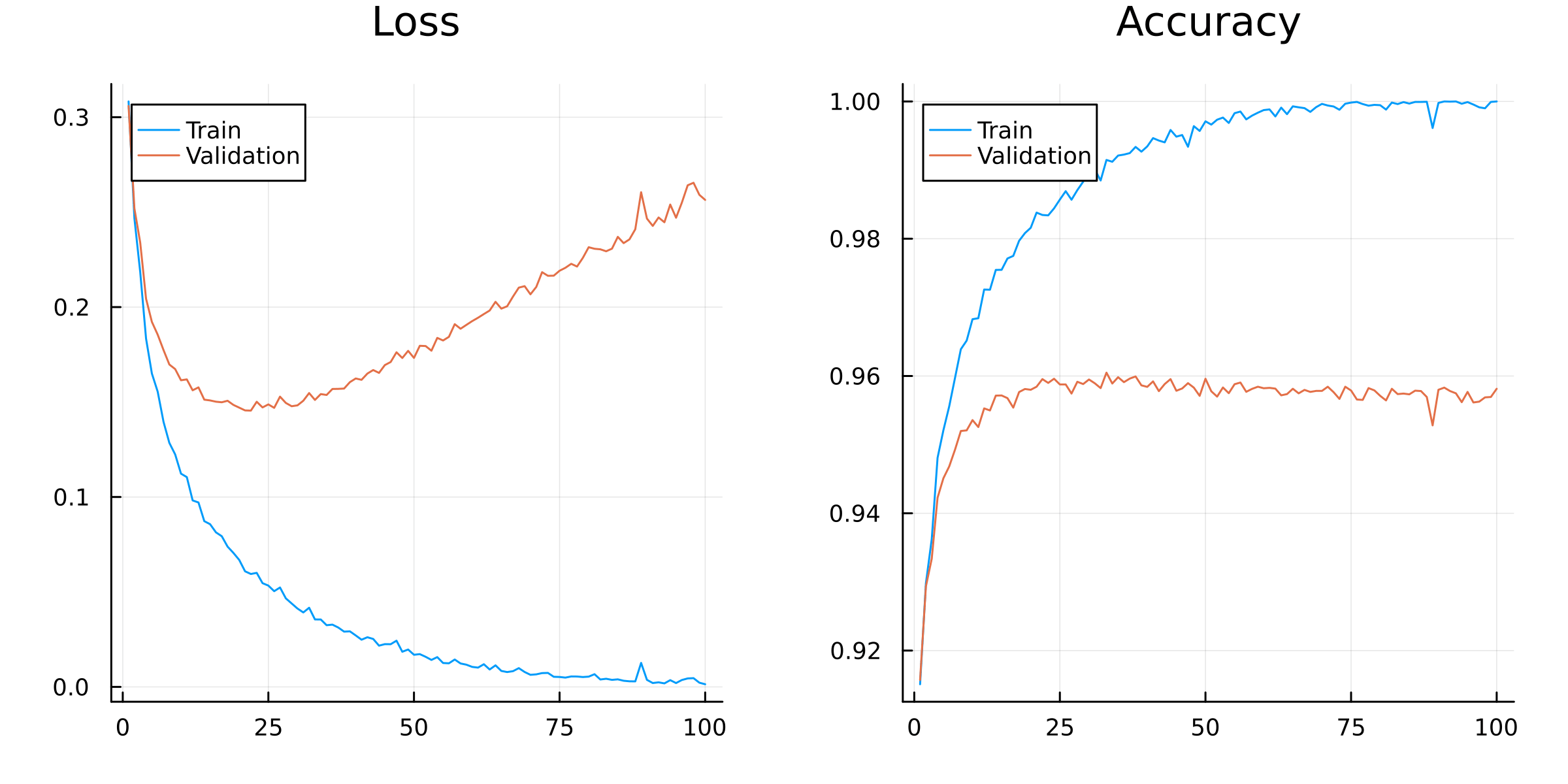
# Training loop:for epoch in1:nepochsfor (i, data) inenumerate(train_set)# Extract data: input, label = data# Compute loss and gradient: val, grads = Flux.withgradient(model) do m result =m(input)loss(result, label)end# Detect loss of Inf or NaN. Print a warning, and then skip update!if !isfinite(val)@warn"loss is $val on item $i" epochcontinueend Flux.update!(opt_state, model, grads[1])end# Monitor progress: acc_train, acc_val =accuracy(model, train_set), accuracy(model, val_set) loss_train, loss_val =avg_loss(model, train_set), avg_loss(model, val_set) results =Dict(:epoch => epoch,:acc_train => acc_train,:acc_val => acc_val,:loss_train => loss_train,:loss_val => loss_val )push!(log, results)# Print progress: vals =Matrix(results_df[2:end,[:loss_train,:loss_val]]) plt = UnicodePlots.lineplot(1:epoch, vals; name=["Train","Validation"], title="Loss in epoch $epoch", xlim=(1,nepochs)) UnicodePlots.display(plt)end
Figure 2.2 shows the training and validation loss and accuracy over epochs. The model is overfitting, as the validation loss increases after bottoming out at around epoch 20.