dir = FastAI.load(datasets()["oxford-iiit-pet"])"/Users/FA31DU/.julia/datadeps/fastai-oxford-iiit-pet"FastAI.jl
He we are closely following the FastAI.jl tutorials on data containers, siamese image similarity
We can load the Pet dataset as follows:
dir = FastAI.load(datasets()["oxford-iiit-pet"])"/Users/FA31DU/.julia/datadeps/fastai-oxford-iiit-pet"readdir(dir)2-element Vector{String}:
"annotations"
"images"img_dir = joinpath(dir, "images")"/Users/FA31DU/.julia/datadeps/fastai-oxford-iiit-pet/images"FastAI.jl convention
Using FastAI.jl convention, we can load a single image as follows:
files = loadfolderdata(img_dir; filterfn=FastVision.isimagefile)
p = getobs(files, 1)"/Users/FA31DU/.julia/datadeps/fastai-oxford-iiit-pet/images/Abyssinian_1.jpg"We can see that the file names contain the pet breed.
Using regular expressions, we can extract the pet breed from the file name:
re = r"(.+)_\d+.jpg$"
fname = pathname(p)
label_func(path) = lowercase(match(re, pathname(path))[1])
label_func(fname)"abyssinian"Now lets check how many unique pet breeds we have:
labels = map(label_func, files)
length(unique(labels))37We can create a function that loads an image and its class:
function loadimageclass(p)
return (
@. loadfile(p), # broadcasting to make compatible with minibatching
@. pathname(p) |> label_func
)
end
image, class = loadimageclass(p)
@show class
imageclass = "abyssinian"
Finally, we can use mapobs to lazily load all the images and their classes:
data = mapobs(loadimageclass, files);@show numobs(data)
image, label = getobs(data, 1)numobs(data) = 7390(RGB{N0f8}[RGB{N0f8}(0.118,0.149,0.106) RGB{N0f8}(0.118,0.149,0.106) … RGB{N0f8}(0.161,0.192,0.141) RGB{N0f8}(0.157,0.188,0.137); RGB{N0f8}(0.114,0.145,0.102) RGB{N0f8}(0.114,0.145,0.102) … RGB{N0f8}(0.165,0.196,0.145) RGB{N0f8}(0.157,0.188,0.137); … ; RGB{N0f8}(0.047,0.075,0.043) RGB{N0f8}(0.043,0.071,0.039) … RGB{N0f8}(0.059,0.09,0.047) RGB{N0f8}(0.059,0.09,0.047); RGB{N0f8}(0.047,0.075,0.043) RGB{N0f8}(0.043,0.071,0.039) … RGB{N0f8}(0.059,0.09,0.047) RGB{N0f8}(0.059,0.09,0.047)], "abyssinian")FastAI.jl convention
Contrary to fast.ai, FastAI.jl separates the data loading and container generation from the data augmentation. From the documentation:
In FastAI.jl, the preprocessing or “encoding” is implemented through a learning task. Learning tasks contain any configuration and, beside data processing, have extensible functions for visualizations and model building. One advantage of this separation between loading and encoding is that the data container can easily be swapped out as long as it has observations suitable for the learning task (in this case a tuple of two images and a Boolean). It also makes it easy to export models and all the necessary configuration.
First, we follow the standard procedure to split the data into training and validation sets:
train_data, val_data = splitobs(data; at=0.8, shuffle=true)(ObsView(::MLUtils.MappedData{:auto, typeof(loadimageclass), ObsView{MLDatasets.FileDataset{typeof(identity), String}, Vector{Int64}}}, ::Vector{Int64})
5912 observations, ObsView(::MLUtils.MappedData{:auto, typeof(loadimageclass), ObsView{MLDatasets.FileDataset{typeof(identity), String}, Vector{Int64}}}, ::Vector{Int64})
1478 observations)Next, we define the data augmentation task separately as a BlockTask:
_resize = 128
blocks = (
Image{2}(),
Label{String}(unique(labels)),
)
task = BlockTask(
blocks,
(
ProjectiveTransforms(
(_resize, _resize),
sharestate=false,
buffered=false,
),
ImagePreprocessing(buffered=false),
OneHot(),
)
)
describetask(task)SupervisedTask summary
Learning task for the supervised task with input Image{2} and target Label{String}. Compatible with models that take in Bounded{2, FastVision.ImageTensor{2}} and output OneHotLabel{String}.
Encoding a sample (encodesample(task, context, sample)) is done through the following encodings:
| Encoding | Name | blocks.input |
blocks.target |
|---|---|---|---|
(input, target) |
Image{2} |
Label{String} |
|
ProjectiveTransforms |
Bounded{2, Image{2}} |
||
ImagePreprocessing |
Bounded{2, FastVision.ImageTensor{2}} |
||
OneHot |
(x, y) |
OneHotLabel{String} |
We can apply the augmentation to the data as follows:
batchsize = 3
train_dl, val_dl = taskdataloaders(train_data, val_data, task, batchsize)(DataLoader(::FastAI.TaskDataset{ObsView{MLUtils.MappedData{:auto, typeof(loadimageclass), ObsView{MLDatasets.FileDataset{typeof(identity), String}, Vector{Int64}}}, Vector{Int64}}, SupervisedTask{NamedTuple{(:input, :target, :sample, :encodedsample, :x, :y, :ŷ, :pred), Tuple{Image{2}, Label{String}, Tuple{Image{2}, Label{String}}, Tuple{Bounded{2, FastVision.ImageTensor{2}}, FastAI.OneHotTensor{0, String}}, Bounded{2, FastVision.ImageTensor{2}}, FastAI.OneHotTensor{0, String}, FastAI.OneHotTensor{0, String}, Label{String}}}, Tuple{ProjectiveTransforms{2, NamedTuple{(:training, :validation, :inference), Tuple{DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.Crop{2, DataAugmentation.FromRandom}}, DataAugmentation.PinOrigin}}, DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.Crop{2, DataAugmentation.FromCenter}}, DataAugmentation.PinOrigin}}, DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.PadDivisible}, DataAugmentation.PinOrigin}}}}}, ImagePreprocessing{N0f8, 3, RGB{N0f8}, Float32}, OneHot{DataType}}}, Training}, parallel=true, shuffle=true, batchsize=3, collate=Val{true}()), DataLoader(::FastAI.TaskDataset{ObsView{MLUtils.MappedData{:auto, typeof(loadimageclass), ObsView{MLDatasets.FileDataset{typeof(identity), String}, Vector{Int64}}}, Vector{Int64}}, SupervisedTask{NamedTuple{(:input, :target, :sample, :encodedsample, :x, :y, :ŷ, :pred), Tuple{Image{2}, Label{String}, Tuple{Image{2}, Label{String}}, Tuple{Bounded{2, FastVision.ImageTensor{2}}, FastAI.OneHotTensor{0, String}}, Bounded{2, FastVision.ImageTensor{2}}, FastAI.OneHotTensor{0, String}, FastAI.OneHotTensor{0, String}, Label{String}}}, Tuple{ProjectiveTransforms{2, NamedTuple{(:training, :validation, :inference), Tuple{DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.Crop{2, DataAugmentation.FromRandom}}, DataAugmentation.PinOrigin}}, DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.Crop{2, DataAugmentation.FromCenter}}, DataAugmentation.PinOrigin}}, DataAugmentation.Sequence{Tuple{DataAugmentation.CroppedProjectiveTransform{DataAugmentation.ScaleKeepAspect{2}, DataAugmentation.PadDivisible}, DataAugmentation.PinOrigin}}}}}, ImagePreprocessing{N0f8, 3, RGB{N0f8}, Float32}, OneHot{DataType}}}, Validation}, parallel=true, batchsize=6, collate=Val{true}()))Let’s quickly verify that the images look as expected:
showbatch(task, first(train_dl))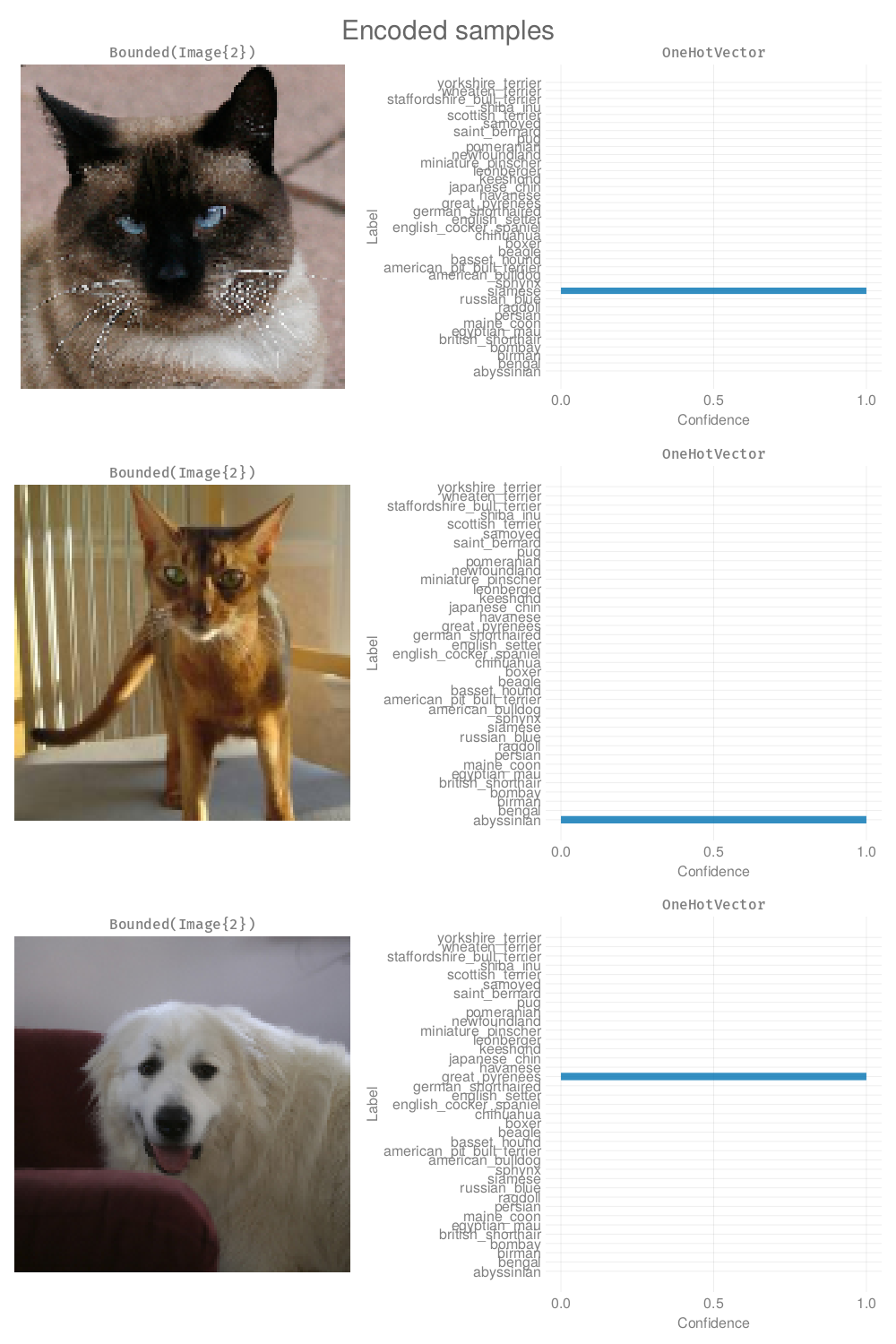
Finally, we can build our model as follows. First, we define the backbone:
# Get backbone:
_backbone = Metalhead.ResNet(18, pretrain=true).layers[1][1:end-1]Chain(
Chain(
Conv((7, 7), 3 => 64, pad=3, stride=2, bias=false), # 9_408 parameters
BatchNorm(64, relu), # 128 parameters, plus 128
MaxPool((3, 3), pad=1, stride=2),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
NNlib.relu,
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
NNlib.relu,
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
),
),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
Chain(
Conv((1, 1), 64 => 128, stride=2, bias=false), # 8_192 parameters
BatchNorm(128), # 256 parameters, plus 256
),
Chain(
Conv((3, 3), 64 => 128, pad=1, stride=2, bias=false), # 73_728 parameters
BatchNorm(128), # 256 parameters, plus 256
NNlib.relu,
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
NNlib.relu,
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
),
),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
Chain(
Conv((1, 1), 128 => 256, stride=2, bias=false), # 32_768 parameters
BatchNorm(256), # 512 parameters, plus 512
),
Chain(
Conv((3, 3), 128 => 256, pad=1, stride=2, bias=false), # 294_912 parameters
BatchNorm(256), # 512 parameters, plus 512
NNlib.relu,
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
NNlib.relu,
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
),
),
),
) # Total: 45 trainable arrays, 2_782_784 parameters,
# plus 30 non-trainable, 4_480 parameters, summarysize 10.649 MiB.
Here we have removed the final layer of the ResNet model, because we will instead use a custom head. We could use the taskmodel function to build the model with an appropriate head automatically:
model = taskmodel(task, _backbone)
model.layers[end]Chain(
Parallel(vcat, AdaptiveMeanPool((1, 1)), AdaptiveMaxPool((1, 1))),
Flux.flatten,
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 512, relu; bias=false), # 262_144 parameters
),
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 37; bias=false), # 18_944 parameters
),
) # Total: 6 trainable arrays, 283_136 parameters,
# plus 4 non-trainable, 2_048 parameters, summarysize 1.089 MiB.
Equivalently, we could have obtained an appropriate head as follows,
h, w, ch, b = Flux.outputsize(_backbone, (_resize, _resize, 3, 1))
_head = Models.visionhead(ch, length(unique(labels)))Chain(
Parallel(vcat, AdaptiveMeanPool((1, 1)), AdaptiveMaxPool((1, 1))),
Flux.flatten,
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 512, relu; bias=false), # 262_144 parameters
),
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 37; bias=false), # 18_944 parameters
),
) # Total: 6 trainable arrays, 283_136 parameters,
# plus 4 non-trainable, 2_048 parameters, summarysize 1.089 MiB.
and then construct our model by chaining the backbone and head:
Chain(_backbone, _head)Chain(
Chain(
Chain(
Conv((7, 7), 3 => 64, pad=3, stride=2, bias=false), # 9_408 parameters
BatchNorm(64, relu), # 128 parameters, plus 128
MaxPool((3, 3), pad=1, stride=2),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
NNlib.relu,
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
NNlib.relu,
Conv((3, 3), 64 => 64, pad=1, bias=false), # 36_864 parameters
BatchNorm(64), # 128 parameters, plus 128
),
),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
Chain(
Conv((1, 1), 64 => 128, stride=2, bias=false), # 8_192 parameters
BatchNorm(128), # 256 parameters, plus 256
),
Chain(
Conv((3, 3), 64 => 128, pad=1, stride=2, bias=false), # 73_728 parameters
BatchNorm(128), # 256 parameters, plus 256
NNlib.relu,
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
NNlib.relu,
Conv((3, 3), 128 => 128, pad=1, bias=false), # 147_456 parameters
BatchNorm(128), # 256 parameters, plus 256
),
),
),
Chain(
Parallel(
addact(NNlib.relu, ...),
Chain(
Conv((1, 1), 128 => 256, stride=2, bias=false), # 32_768 parameters
BatchNorm(256), # 512 parameters, plus 512
),
Chain(
Conv((3, 3), 128 => 256, pad=1, stride=2, bias=false), # 294_912 parameters
BatchNorm(256), # 512 parameters, plus 512
NNlib.relu,
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
),
),
Parallel(
addact(NNlib.relu, ...),
identity,
Chain(
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
NNlib.relu,
Conv((3, 3), 256 => 256, pad=1, bias=false), # 589_824 parameters
BatchNorm(256), # 512 parameters, plus 512
),
),
),
),
Chain(
Parallel(vcat, AdaptiveMeanPool((1, 1)), AdaptiveMaxPool((1, 1))),
Flux.flatten,
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 512, relu; bias=false), # 262_144 parameters
),
Chain(
BatchNorm(512), # 1_024 parameters, plus 1_024
identity,
Dense(512 => 37; bias=false), # 18_944 parameters
),
),
) # Total: 51 trainable arrays, 3_065_920 parameters,
# plus 34 non-trainable, 6_528 parameters, summarysize 11.740 MiB.
With the model defined, we can now create a Learner object from scratch:
# Task data loader for new batch size:
batchsize = 64
train_dl, val_dl = taskdataloaders(train_data, val_data, task, batchsize)
# Set up loss function, optimizer, callbacks, and learner:
lossfn = Flux.Losses.logitcrossentropy
optimizer = Flux.Adam()
error_rate(ŷ, y) = mean(onecold(ŷ) .!= onecold(y))
callbacks = [ToGPU(), Metrics(error_rate)]
learner = Learner(
model, (train_dl, val_dl),
optimizer, lossfn,
callbacks...
)Learner()FastAI.jl way
Most of the manual jobs above can be done automatically using the tasklearner function:
learner = tasklearner(
task, train_data, val_data;
backbone=_backbone, callbacks=callbacks,
lossfn=lossfn, optimizer=optimizer, batchsize=batchsize,
)Learner()Note that in this case, we pass on the raw, non-encoded data to the tasklearner function. This is because the tasklearner function will automatically encode the data using the task object.
We will begin by using the learning rate finder to find a good learning rate:
res = lrfind(learner)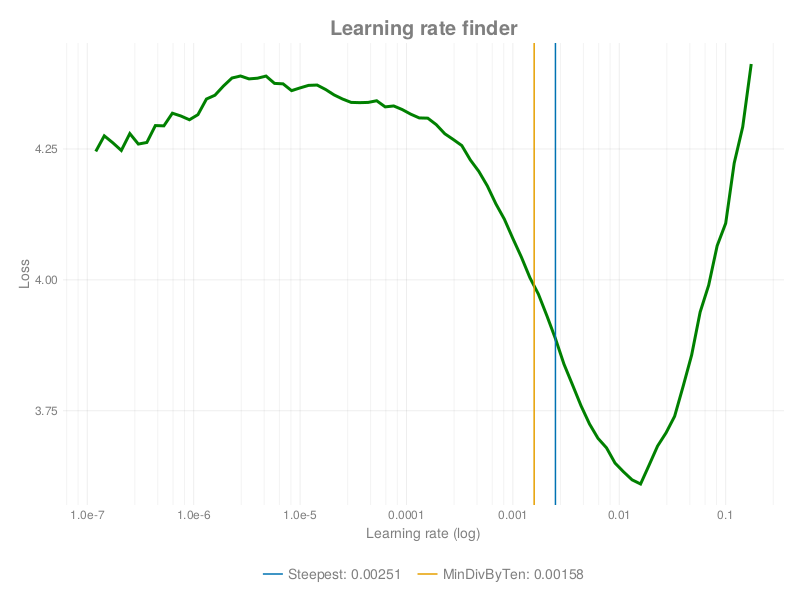
Below we fine-tune the model for 5 epochs and then save it to disk:
finetune!(learner, 5, 2e-3)Note that by default, this will train the model for one epoch with pre-trained weights (our _backbone) completely frozen. In other weights, only the parameters of our _head will be updated during this epoch, before the second phase of training begins.
Now we will fit the whole training cycle:
fitonecycle!(learner, 5, 2e-3)
savetaskmodel("artifacts/c5_resnet.jld2", task, learner.model, force=true)Using our model, we can now make predictions on the validation set as follows:
task, model = loadtaskmodel("artifacts/c5_resnet.jld2")
samples = [getobs(data, i) for i in rand(1:numobs(val_data), 3)]
images = [sample[1] for sample in samples]
_labels = [sample[2] for sample in samples]
preds = predictbatch(task, model, images; device = gpu, context=Validation())┌ Info: The GPU function is being called but the GPU is not accessible.
└ Defaulting back to the CPU. (No action is required if you want to run on the CPU).3-element Vector{String}:
"bombay"
"persian"
"bombay"The accuracy is given by:
acc = sum(_labels .== preds) / length(preds)1.0We can visualize the predictions as follows:
showsamples(task, collect(zip(images, preds)))